


A Smaller SRAM Cell with Ribbons
3 ports, one for Write and 2 for Read

I’ve been thinking for a while about an SRAM cell organized more like a logic cell, with CMOS pairs between two rails and expanding along the rail. When Fred Chen posted about a 3nm academic model this was the push I needed to give the SRAM layout a try and figure out how to wire it into an array

The Georgia Institute of Technology publication discussed both fin and ribbon FETs at the same size. I chose to go with ribbon FET, because it is the new hotness of course, but I made a few slight changes:
I use a CPP of 45nm instead of the 42nm assumed in the paper. This will match better for my interests in a low power process where 3nm extra channel length will be a useful reduction in leakage.
I assume the Intel nano-TSV method of backside power, which directly contacts the source/drain from behind instead of using a buried power rail, because I was curious to see if it helps density (it does).
I also made a big change - I assume electron-beam lithography is used. This frees me up to use 2D patterns in the metals, although they remain mostly linear. It is possible the patterns I show here could be made with EUV and dual masking but I surely broke some layout rules. EBL is a lot easier, it does not have a directional preference for each layer. In the spirit of “what is possible?” I added EBL to the mix.
Disclaimers
As with the Mock4 rules I used, these “Festive3” rules for ribbons are entirely untested and unproven. I am sure my wiring has multiple rule violations if you tried running them through EDA to check if they are manufacturable. However, I do believe Festive3 uses feasible physics and represents fair goals for sizes, lithography, and the uses of vias and wires.
I also make no representation that no IP claims would apply if you followed this design - someone almost always has something to claim on any technology that is not crazy (and on many that are crazy). I am not liable for such claims upon your uses.
I make no representations this design will work correctly. Do your own testing and verification if you want to try it. Contact me if you would like my help or review.
If you do use this cell design with the wide layout of an 8T, 1W2R cell and assists from one-sided reads or N-Latch writes, do cite this work as a reference. Thanks!
Now, lets get on with the post.
The Ribbon Pattern
Ribbons are built on top of the substrate and surrounded by source/drain contacts and gates, similar to FinFETs.

Where FinFETs would have 2 or 3 fins side by side, a ribbon FET has ribbons stacked above each other. The ribbons occupy about the same width as 2 fins, as the GA Tech paper illustrates. The fins will give better channel control than fins, less leakage, for a similar channel length.

This is because the gate wraps all four sides of each ribbon. Also, you can scale up to 3 or even 4 ribbons in a stack for a stronger transistor with the same area footprint, while FinFETs with more fins take up more area. I expect 2 ribbons will be fine for SRAM with narrow ribbons (15nm wide) since SRAM is best when it sips power, but you could execute this design with more ribbons in a stack, as well as it could be tried with just 1 ribbon.
All Transistors are Created Equal
Continuing with the similarities to fins, the N- and P- transistors made with ribbons have roughly equal drive. Indeed, the P- ribbons may be a little stronger than the N- ribbons since compression stress is easy to maximize when the ribbon is completely surrounded. This means that we need assist in the SRAM cell, as discussed in the introductory post for SRAM, since there needs to be a functional hierarchy:
the writing current must overcome the internal feedback loop inside the cell
the internal feedback must overcome the current drain from a read operation
The SRAM is a building block of digital circuits, but the cell itself is an analog puzzle.
In the classic SRAM approach the cell is tall, spanning several rails, and it has either 6 or 8 transistors (single or dual port) but it actually occupies an 8- or 12-transistor space, with some fins cut to both isolate the cell where an edge cannot be shared and to weaken the P-transistors to create that asymmetry. It still needs an assist in writing, generally overdriving the access transistors.
The approach I show here based on a “logic style” wide arrangement has 8 transistors in an 8-transistor space.

The logical circuit is shown left, in the middle is a cartoon of three bit-cells stacked vertically, and the physical silicon and wiring layout for one bit is rendered at the right.
All four sides of this cell share with the neighbors. There is no inactive space in this layout, no stress relief and all transistors roughly equal strength. This arrangement requires an assist for writing, and an assist for reading.
The reading assist is simple - single-sided read is used. Just one P-transistor is used to make a read, so it only loads half the cell. Its load will be a floating wire which limits the total current that will flow. Each cell can provide access from the left, or from the right, making 2 read ports. The ports cannot both be used at the same time. The N-transistors are used only for writing.
The write assist is a little more unusual, although write assists using reduced voltage supply are known. In this design the N-transistors use a combined N-latch, similar to the NLAT arrangement used in DRAM sense amps. The joined sources for the internal N-transistors are tied to the gates of the access N-transistors, with the current and voltage for this junction being driven by the write-enable word line. The word enable is normally pulled low, towards Vss, while the cell is holding data. The word enable is pulsed towards Vdd when it is time to input new data. The gates of the access N-transistors and the inner N-transistors’ source voltage are pulled up to Vdd which erases the old cell value. The Data-In signal (which is paired with its own inverse on the other side) is stronger than the interior transistors as the pulse reverses down and the N-transistors start to operate while the interior value has not yet formed. As the enable pulse ends and the source voltage is pulled back down to Vss the internal feedback is weak, with no internal value set. One of the bit-lines of data-in, and its paired inverse, must be in the low voltage state which will render that side’s N-transistor to be on, so the new value is injected into the cell before the access transistors return to their off state.
Build the Local Wiring
If we zoom out a little from the one cell we can see how it shares with neighbors.
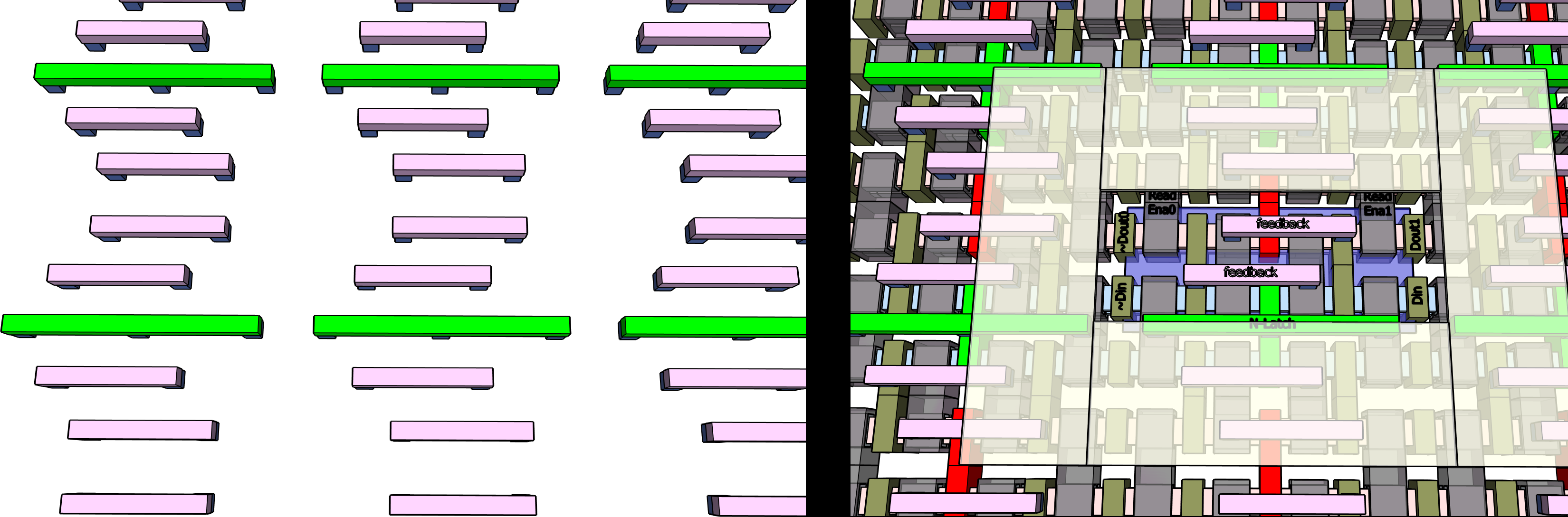
The only wiring needed local to a cell is the Metal-0 and the Via-0 plugs which connect the metal to gates or source/drain contacts. The gates and source/drain are mostly double-length, spanning a P-ribbon and an N-ribbon, so they are providing local wiring as well.
You will not see a wire to the Vdd (positive) side of the cell because in the ribbon era it is expected that backside power delivery via a nano-TSV will be the norm. The low-side voltage for the cell will come over a front side wire attached to the N-Latch node. This is a signal wire because it is pulsed positive when capturing input data. The drive for that signal will be discussed later in this post (and will have both Vss and Vdd backside power).
Bring in the Word Enables
There are three word enables, one for the write port and two for the read ports, and they run from top to bottom as we saw in the classic “tall” SRAM designs.

You will see the two read enables connect to their vias using some cute little tabs, which would be a design rule violation with optics, including EUV, at this scale (those wires are around 20nm wide). But I am assuming electron beam lithography (EBL) for this exercise, to see the limits of scaling when the transistors are supported with ideal wiring, and EBL has no need of “directional illumination” which is fundamental to how the finest optical lithography works.
There are alternatives, for example the wires could be simple and straight, while the vias could be stretched horizontally for example using pattern shaping. The landing zone at the bottom of these vias should permit that.
The reason these tabs are used is to improve clearance on the vias which come next, which are used for the data inputs and outputs.
Move Data In
The data flows horizontally. The cell is only 80nm tall so there is only space for two horizontal connects per metal layer. The design here has the data input pair, Din and its inverse ~Din, on the first horizontal, Metal 1. Vias are shown linking directly from the M1 down to the source/drain contacts, for simplicity.

In practice these vias may be built in 2 or 3 stages stacked up. Multiple stages simplify the etching but make the lithography more crowded, although EBL should be able to handle the pattern accurately in either approach.
Move Data Out
Another two horizontal wires are needed for the data out, and these will be placed on the next level up, M4. This sequence skipped M3, which will run vertical and used in other parts of the chip but is not needed for the SRAM. The choice of which pair is on which layer is arbitrary and could be swapped, the actual choice will depend on electrical simulation and layout in drive and relay circuits.

The Zero port is always inverted, ~Dout0, since it connects to the side of the cell where ~Din arrives. The One port, Dout, is not inverted and reads the Din side.
The data in and data out lines also are shown with tabs. The reason is because the vias are alternating, normal and inverted signals, on the same horizontal line. An alternative solution would be to use sinusoidal lines in pairs with just enough curve to alternate which one of the pair is over each via. That might be possible even with optical lithography, since the pair could pitch split from a larger line more easily drawn. The M2 and M4 layers could snake in offset rhythm to reduce crosstalk.
However, the details will depend upon the real chips and real processes. My goal here is to be persuasive about what is possible: if I leave a few reasonable difficulties to be solved, that is fine so long as they are not impossibilities.
Drum Roll - Cell Size
The dimensions I borrowed from the GA Tech paper, and even relaxed slightly, are:
Contacted Poly Pitch (CPP), the distance from source center to drain center and thus the width of a CMOS pair, is 45nm.
Ribbons are 15nm wide and space on a 40nm repeating pitch, allowing 25nm between them for the surrounding dielectrics, gate metals and source/drain materials, as well as insulating spacers.
There are no rails for power or ground between the ribbons, as you can see in the early image of how the ribbons are built up on the substrate.
These result in a cell height of 80nm (one P ribbon, one N ribbon) and 180nm wide (4 P and N transistor pairs), for a total predicted cell size of 14,400 nm^2.
Performance
The size seems quite promising, for the functionality of 1 write and 2 read ports. As is the norm, these ports apply to an array of many words (columns, in these illustrations). Each word can only do one operation at a time, so there needs to be logic which ensures the three ports are all working on different words in any one cycle.
I do expect this will not be the fastest SRAM. Single ended read ports need the data lines to be pulled low and then isolated before reading, which will take an extra half clock. However, the P-transistors are expected to be strong and nothing compromises the internal feedback strength so the pull up action from the cell should be good. Some assist is available if the data line is sectioned and floating before the read access opens, so its capacitance is moderate, reducing the current drain for reading.
The N-Latch mechanism for writing requires strong buffers to drive it since the pulse in current when capturing new data and both transistors are weakly on may be more than is usual for driving gate loads, but this mechanism is proven in DRAM where 512 or more NLATs may be driven simultaneously on one access wire. The sizing needs to be careful, and clearing the prior value will take at least a half clock.
On the positive side both the assists are well defined and should yield good noise immunity. The NLAT mechanism is suitable for low voltage use, and the size calculations allow for a generous channel length to minimize leakage. There are reasons to expect this design to be useful.
Putting it Together
Time for the video!
Auxiliary Circuits
The supporting cast of this SRAM is much the same as in the previous post. In particular the address selectors and the Din/~Din drivers and repeaters will be the same logical circuits mapped onto the ribbon logic.
The single-sided data output will be different, and a bit simpler.

It is a dynamic circuit. At normal times the strobe is off, so the bit-line is pulled down to Vss and the wired-NAND output is pulled up to Vdd. When the read strobe is pulsed both the input drivers switch off, leaving those lines to float. One cell from each word is attached to the bit-line and if that bit is a 1 in a selected word then the data line is pulled up, the output is pulled down. We can repeat this pattern with a single wired NAND on a higher layer metal aggregating the pull downs from multiple sections. Only one word is ever active, so at most one pull-down occurs. The signal may not last more than 10s of nsec because of leakage but that is easily long enough to capture the output with a D-FlipFlop at the end of the wired-NAND output.
On the vertical direction the write enables will need to use extra strength boost transistors to launch them into the array and provide boost if the word is long. This is because the N-latch operation may require a pulse of current as the cells pass through the half-on half-off phase of their voltage shift. This strength may come from using multiple transistors in parallel.
Other than that, things are the same. We need 3 address selectors for the 3 ports. The bit cells should be the same height as the supporting cells - the logic area does not need space for Vdd and Vss rails because of the backside power from nano-TSVs. The supports will scale smaller on Festive3 just like the memory cells do.
Overall, I expect the overheads in the supporting cast will be a larger proportion than for the Mock4 dual-port design, perhaps 30% overhead on a 256-word by 288-bit array. That would bring the effective cell size in that array to 20,000 nm^2.
Next Week
The next post will be the report on locating the direction of the Sun, to about 1/10,000th of a degree, using GNSS satellite position data.
After that a short pause as I build out and verify a design for a minimal energy per operation matmul capable of handling MX “microscaled” i4, i8, and FP6 data. That will likely result in a short series of 5 or more posts.
Did you see a problem with this design sketch? I welcome comments and messages about topics in Poratbo, including suggestions for future topics.