



67 years ago Dr. Robert Dennard invented the single transistor, single capacitor circuit for dynamic random access memory or dram.

This “1T1C” invention was not used in the earliest DRAM chips but ten years after his invention 1T1C had become dominant in essentially the modern form we see today (Proebsting MOSTEK 1977), crucially combined with the invention of an effective “sense-amp” circuit which both read and writes well matched to cell size (Stein ISSCC 1972). The DRAM cell was the most common circuit in the world for almost 40 years, since memory cells are far more numerous than logic cells. It was outnumbered by another kind of memory, the NAND cell, about a decade ago.
Dr. Dennard died last week at age 91. He made many other contributions to microelectronics. Inspired by a lecture by Carver Mead on the limits of circuit size, Dr. Dennard distilled the essential, simple scaling relationship, known as Dennard scaling, which held for 30 years until it reached the limits of quantum physics and atomic size. Dennard scaling is often mistaken for Moore's law and was the rock on which Moore’s law stood for its fastest years. Dr. Dennard was a giant of silicon.
There has been a recent quiet but enormous shift in how DRAM is used to construct computers. It is time to think a moment on where Dr. Dennard’s invention goes next.
DRAM Roles Today
There are 4 main varieties of DRAM in the marketplace. These each combine the underlying 1T1C cells with different kinds of package and interface rates. They are:
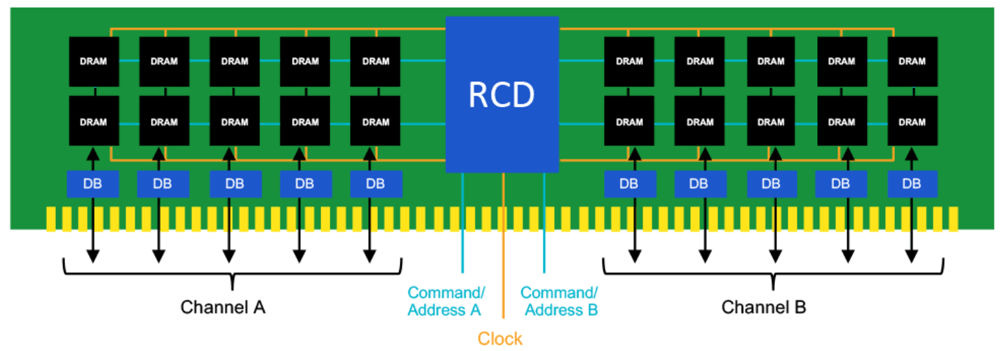
DDR, or Double Data Rate, which transfers 2 bits per signal wire per clock cycle. It was introduced in the 1990s has been the top seller and flagship form of DRAM until 2023. The physical protocol tolerates longer wires, edge connectors with sockets, and 2 or more chips sharing a data wire.

Simplified schematic of a DDR5 edge-connected module (image credit: Micron)
It is practical and normal to have a large number of chips connected to one host channel.
LPDDR, or Low Power DDR, which was invented for mobile devices. Wires between host and memory must be short and data wires go to one DRAM chip.

A 4-chip LPDDR package (image credit: Samsung)
Short wires keep signals fast and low power in a small package which may stack up to 4 chips though each chip has separate data lines to the host. A typical LPDDR chip moves 4x more data than the same generation of DDR.
GDDR, or Graphics DDR, is also designed for relatively small capacities but uses wiring longer than LPDDR running at more power to move data about 4x faster than LPDDR.

Ten GDDR6 chips surrounding an Xbox Series X processor (credit: Microsoft). GDDR chips are packaged individually to meet the exacting standard for the wiring to the host. This is used in graphics controllers and game consoles.
HBM, or High Bandwidth Memory, was invented for the high end of graphics processing, and uses stacked packaging with vertical wires or “vias” that tie up to 12 chips together.

A minimum stack of 4 DRAM chips beside a host (image credit: SK Hynix)
It is required to be adjacent to its host on a high-quality interposer so that 1,024 or more data wires efficiently transfer a large number of bits on every clock cycle. HBM chips have about 4x the bandwidth of a GDDR chip, but the stacking has another 4x multiplier on data rate as sets of 4 chips run in parallel in the stack.



These four kinds have mostly stayed in their own lanes in the market. DDR was mounted on DIMMs, with multiple chips in parallel to get very high-capacity memory including redundant chips for error correction capability for high reliability. Capacity and reliability have been why classic servers used DDR for 30 years.
LPDDR dominates cell phones and tablets, and has an increasing share of laptops although DDR has remained in use on laptops since the LPDDR was assumed by most customers to be low performance just because it is found in lower end devices. Apple thought differently, as we will discuss in a moment.
GDDR is the smallest market segment. It is used in add on cards for graphics and in games consoles like Xbox and Play Station. It is more widely used for graphics than HBM due to its commodity pricing. DDR, LPDDR, and GDDR are commodity priced at about the same dollars per GB of capacity. Internally, all DRAMs from a given vendor in a given generation (DDR5, LPDDR5, GDDR6 are the most recent generation) will share the design of the core arrays of bits. Around those cores the different kinds of chip are defined by investments in the interface circuitry to support the speed and signaling difference distance.
HBM is the most distinct flavor of DRAM. It does share the core memory cell technology with the other kinds, but the investment in interfaces is far higher and the complex packaging has no equivalent in the other kinds of memory. Almost half of an HBM chip is taken up by the interfacing including the Through-Silicon Via (TSV) area needed to support the wiring which travels vertically through the chip from top to bottom so that they can be stacked one on the other and connect to a base chip at the bottom of the stack which converts their signals for interfacing to the host chip. HBM pricing numbers are kept secret but for medium-volume purchase it is rumored HBM costs about five times as much per GB as the commodity flavors of DRAM.
The Spotlight Dims for DDR5
I did not want to write a history lesson, just set some context. Let’s now get to the big event in the past year and look at the reasons why this is a step change, not merely gradual evolution, for DRAM flavors.
Here is the current top-of-the-line rack-mounted server from Apple:

If you click through the link to see the specs, you will notice it cites up to 192GB of memory at 800 GB/s of bandwidth.
Here is the latest server announcement from Nvidia:

The specs on that board include 480GB of usable memory at over 16 TB/s bandwidth and it is planned for scaling up to clusters of 7,500 such boards.
The two largest, most valuable computing vendors each dominant in their market, and what do you notice them not using even in their largest, most powerful offerings?
DDR5. Nowhere. Not as a DIMM, not hidden in a separate box. Not coming in any future upgrade. Vanished.
And what is also very obvious? Huge, crushing performance, at very low power per bit of memory moved, redefining expectations for memory.
DIMMs are fading away. DDR5 will ship for some years yet, but the money and reasons for new engineering will have moved to other variants.
Will LPDDR Play the Lead?
Sort of - but it will not be LPDDR as we have known it.
On both the Apple and the Nvidia machines LPDDR5x is used today. So you would think that makes LPDDR6 an obvious next generation? Not really. The next chip has big shoes to fill. BIG capacity and reliability shoes. Urgently.
Nvidia and Apple, and some others, are using LPDDR5x as the least bad choice. DDR5 was simply infeasible at the rates and efficiency required, but LPDDR was flawed too. Just not impossible as a short-term solution. The next chip generation really needs to have a single replacement for both LPDDR and DDR lines. It would be a mistake for the next generation of the DRAM family to simply inherit from LPDDR5. Instead, if we look at the future instead of the past, this is clearly the moment for a new flavor of DRAM which will use dual inheritance to better meet this revolution in the market in both mobiles and servers.
I’ll be corny and call it AI-DDR. It will look a lot like LPDDR5, but will fill the capacity and reliability needs more like DDR5 did.
What are the Reliability Needs?
LPDDR5 and DDR5 implement on-chip single bit repair. This is not trustworthy ECC. Field data shows a surprisingly large fraction of DRAM faults are multibit which are not correctable on the chip, and LPDDR5 has no way for these failures to be detected or reported to the host. An estimated 10 FIT per chip of failures will pass undetected, so that calculations following that data may be corrupt. On a terabyte server that would be around 5,000 FIT or about 4% per year. Undetectable faults are especially nasty, and this level is unacceptable.
There is the separate problem of security. Modern systems also have vulnerabilities to disturb events, both accidental and malicious, and ECC with fault detection is an essential tool in blocking and detecting such “Row Hammer” attacks. If a system with multiple users has a disturbance vulnerability that can be an even more serious problem than ordinary faults. The on-chip single bit ECC is not useful for security.
Host chips can muddle through by adding “inline ECC” to get acceptable reliability but it comes at significant costs in reserved DRAM capacity, cache, host chip controller complexity, and worst-case patterns that will cause some algorithms up to 50% reduction in throughput.
HBM3e shows a possible path for reliability and security. AMD and others persuaded JEDEC to provide some serious reliability in HBM3e, which was heroic considering the weak ECC that was standardized in DDR5 and LPDDR5 at the same time. The HBM3e chips provide 24 extra bits per 256 bits of data. This allows them to make 2 bytes of correction per 512 bits of data and then use a 16-bit CRC to detect if the correction was unsuccessful. The result is about a 10x reduction in failures but more than 100,000x reduction in undetected failures. This makes for improved reliability with excellent probity (trust in using only correct data).
This might be enough for AI DDR. But wait, you DDR5 fans will have noticed that this is far less than the “chipkill” ECC we have on DIMMs. Well, all is not lost.
A lot of existing reliability is over-engineered and just repeating legacy patterns. Field data shows there are significant causes of failure due to the DIMM itself. A DIMM fails about as much as whole chips. BGA packages have better electricals for faster data transfer and they will fail much less than DIMMs. BGAs can be replaced in the field if the server is designed for access to them.
If you really want chip-kill class reliability you can do it with BGA packaging. For example, add a 5th chip to each package and use all 5 chips in parallel like a DIMM. A compact and higher reliability DIMM! You can even desolder and replace a BGA in manufacture or in the field (I am not recommending that, a similar risk as replacing a DIMM). You give up on some performance advantages of independent DRAM chips but get the “traditional” reliability check-box.
We certainly can do better than LPDDR5. We should probably do better than HBM3e. After all, HBM3e was a compromise negotiated 3 years ago for a class of memory never expected to reach terabyte scale - surprise! They are TB-scale and they are not even shipping yet! If we plan for terabyte scale on AI DDR, a better baseline is 32 bits of ECC per 256 bits of data. That allows a nice range of functionality:
repair any 4 bytes in 512 data bits with just a 0.01% chance of a fault incorrectly repaired and then undetected.
repair any 4 contiguous bytes (bounded fault) in 512 data bits while leaving an additional 8 bits of metadata for features like CHERI security or MX grouped data format, still with even lower chance of undetected misrepairs.
repair any 6 bytes in 1024 data bits while also supporting 16 bits of metadata and a yet lower chance of undetected misrepairs.
The next design out of JEDEC will need to fill this new gap and will need to cover 5 years in the market. Let’s get the reliability done right, ok? 32 bits of ECC appended to the data, round tripped to the host chip so the system designer can decide how best to use it. And leave that SB correction to LPDDR5 and DDR5 in other markets.
Scaling out to Big Memory
The other problem we have is that LPDDR5x scales only to 192GB for Apple and 256GB for Nvidia. And they have the best SOC designers on the planet, with Nvidia willing to spend silly money to make Grace able to control stacks on both sides of a high-quality circuit board.
We will need to scale AI DDR to even larger memory capacity. A memory at least 4x as large per host package, and ideally 8x larger, should be a goal already. Over 5 years the market may stretch needs further. Can we take the nice things about DDR but trim some of the obsolete features and add some improvements to what remains?
The major problem with putting directly connected DRAM chips like LPDDR around a host package is the number of signal wires needed and the distance they can be routed. We could make a nice improvement by simply eliminating the Command and Address (CA) wires. There is no reason that CA functions cannot share the DQ wires used for data, instead of compete with data on separate wires. If you need 16 lanes for data, and keep the half-duplex DQ signaling style, you should need just 16 wires running from the host to the DRAM. The CA wires were an overhead that made some sense 30 years ago, mitigated by adding the RCD chip on a DIMM to redistribute those wires, but they just add overhead and inefficiency to designs where every chip works independently. We are not building DIMMs anymore. The separate CA wires are an anachronism.
We are entering an era of 32Gb DRAM chips so that by itself gives us a doubling of capacity (over the 16Gb chips today) in a footprint limited by the number of chips that can be wired to the host. LPDDR also defines a variant operating with a half-width data bus (8 lanes instead of 16), which appears to be in use by both Apple and Nvidia, so bonus points for AI DDR supporting an 8-DQ variant as well. With all traffic running on just 8 lanes and no CA the wires are reduced to 1/3rd, while the 32Gb chips provide a doubling, we are a lot closer to a goal of an 8x capacity jump.
Why stop at 8 wires? We could use 4, like DDR does - but still run the CA on the DQ wires. Especially if the Phy is qualified to run up to about 10cm (BGA at both ends), allowing more packages to be placed around the host. Those big iron folks wanting to work around whole-chip failures can now use 5-chip stacked packages to provide a super-reliable 20-bit wide interface. 10cm traces with no connectors in the path should run 2x as fast as DDR5 ever will. About 512 DQ lanes total will get 2TB/s of throughput and 1TB of capacity if each chip delivers 4 lanes at 32GBps (possibly 16G baud PAM4, like GDDR7). This is likely a nice balance for a GPU supplementing the co-packaged HBM. Finding 512 external lanes and routing them is well within practical range for a modern GPU.
The density of BGA can be quite competitive. A 5-high chip package with 20 TSVs for a high reliability BGA, each chip listening to only 4 wires and the others cleanly bypassed, could deliver 16GB in a square cm footprint - about the same board used as a 128GB DDR5 DIMM in a socket. Taller stacks in BGA should be possible.
You may have noticed “AI DDR” is not just a version of LPDDR. It is multiple heritage, taking some of the best things about LPDDR, DDR, and even GDDR.
Some Fiddly Details
The extra wires in current chips are not just for command and address. They include clocks, a data-invert signal, and a CRC-plus-flags line. Those can all go onto data lines, too, though not all are still required. The data invert is obsolete because all data should be scrambled or encrypted (put a mandate in the spec) so using inversion to avoid worst case signals is unnecessary. CRC becomes ECC and is appended inline as 17th and 18th bits of burst length after 16 bits of data. The encryption also simplifies clock recovery, and we can add a FLIT boundary pattern every 256 clocks or so, or maybe at direction changes on the half-duplex, which includes some status information.
Do these add latency? Nah. The latency gain from having more channels by ruthlessly eliminating excess wires will easily compensate at the host chip level. The real throughput limit will be the operation of the DRAM banks and the half-duplex turns, not the framing bits. Fewer wires makes it easier to optimize what really matters.
Will moving CA and other functions onto the data wires decrease efficiency? No, because data efficiency over all the wires is the real metric, and those other wires carry zero data today. You could look through the other end of the telescope, and say that we will not be moving CA functions on data - we will be moving data on the CA (and other) wires. When all wires are the same, then the question is simply “how many of those universal wires fit a given capacity/bandwidth goal?”. The number of these uniform wires may be 4, 8, 16, or even 32, with the traffic simply reshaped to use the lanes available.
Ideas - Got a Million of Them
Now, I am just throwing out some ideas. I have more if you want them - but this post is long enough. Ideas are easy, making things work is hard. You, dear readers, are encouraged to think up even better ideas.
Sometimes a market shift is big enough that the hard work needs to be done, simple evolution will not keep up. It is crystal clear this already happened to DDR5 - it has fallen so far short that the two largest computer makers have totally abandoned it.
LPDDR5x should not be smug that it has won. It is just sitting on a powder keg of unsatisfied requirements, which need urgent remedy. So urgent that a new flavor of DRAM, possibly a whole new direction in DRAM, should be what JEDEC is working on. This is punctuation, not gentle evolution. It is an ecosystem waiting to be won by a really effective new entrant.
AI workloads are causing us to rethink the legacy patterns from past computing. This is a good time to allow some clean sheet redesign of what a DRAM should be. We have had 30 years of DDR. It should not be a surprise that it is time for a major overhaul to address the large changes happening in computing all around us. The surprise should be that DDR has worked well this long with so little change.
https://www.youtube.com/live/91smpJIFt-4?si=PcA8zzaXTgbJiZ5Y
EFCL Summer School - Keynote #4: Memory-Centric Computing
HotGauge: Methodology for Characterizing Advanced Hotspots in Modern and Next Generation Processors
https://youtu.be/61VJ7KJAgnM?si=XI0cxHg48lxqFInl
Oscillator for adiabatic computational circuitry (US11671054)
Granted Patent | Granted on: 2023-06-06
https://labpartnering.org/patents/US11671054
ITU-T L.1318 : Q factor: A fundamental metric expressing integrated circuit energy efficiency ; Recommendation L.1318. In force components.
https://www.itu.int/rec/T-REC-L.1318/en
https://patents.google.com/patent/US11671054B2/en?oq=Oscillator+for+adiabatic+computational+circuitry+(US11671054)+Granted+Patent+|+Granted+on:+2023-06-06
SUSTAINABLE COMPUTING
Ubiquity, Volume 2021 Issue February, February 2021 | BY Art Scott, TED G. LEWIS
https://ubiquity.acm.org/article.cfm?id=3450612