


Pipe 9: Rotations, KW, and Carry Lookahead
These complete the digest logical functionality

Connecting the slices together
There are 3 sets of bits which travel over long wires to slices which are not adjacent. These are the wires that bring the (K + W) bits in from the scheduler stages, and the wires that support the rotation of eOut and aOut bits that go to following stages.

The straightforward way to implement these is with 3 groups of 32 wires running side to side on the M5 layer. Those wires are modelled with a 60nm pitch so the total covers about 6 microns of the channel, blocking access to higher layers except in a few places. This is not a problem since we have reached the end of our logical functions, and what remains has plenty of space to allow power wiring to get through.
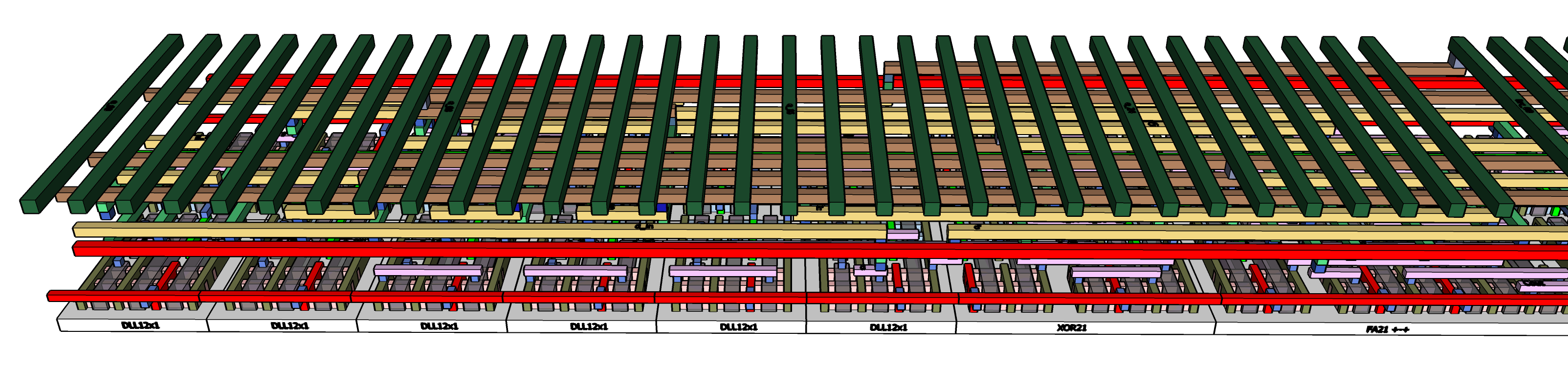
The e-rotations connect 3 distant e-pipes from the previous stage into one pipe of the current stage.

The 4 vias show where the e-rotations and the kw bit are contacted to bring their values down as inputs to the slice. For example, the output from e-pipe 08 of the prior stage is one of the three rotated inputs to e-pipe 00. It is routed through vias and metals until it reaches the input latch.

E-pipe 00 also has rotated inputs from prior stage e-pipes 21 and 26. Although 32 e-rotation wires pass overhead, each stage only uses 3 of them. Each e-pipe only drives one e-rotation wire as an output.

The e-pipe 00 also draws one kw bit as an input, kw 00. The kw wires are driven by the scheduler stage, which this blog essay will not be detailing. there is enough detail for you to absorb with the digest slices!

As each kw wire only has one consumer, there is really no need for the kw[00] wire to continue further. The kw wires can be further optimized by shuffling their order to balance length with the amount of wire needed in the scheduler and to promote less adjacent wiring - but such trimming and shuffling will add nothing to the logical explanation here, so it is left as another exercise for the reader.

The final group of 32 wires comes from the a-rotations delivering a-values from the prior stage to be inputs to the a-pipe.

Three of these rotations are connected down to be inputs to the a-pipe, in the same way as we saw for inputs to the e-pipe.

The a-pipe has no kw input, so that is the last of the major cross-slice wire groups.

Let’s see that again
as a video.
We will continue with a look at how the rotations are driven, and at the carry lookahead.
I welcome discussion of the open section of the post, you can add comments to the Table of Contents for Pipeline post if SubStack will not allow your comments here. Thanks!
Thank you for supporting this blog.
Carry Lookahead
Carry is annoying. It is simple to compute, but the simple way ends up cascading through all slices of an adder. In a 32-bit adder that means 32 stages of operation, worst case, until the operation is finished. In the SHA-256 pipes that would make the final adders of the e-pipe and a-pipe much slower than the rest of the pipes combined.
The logic flows right to left because we write numbers right to left.

The general solution is known as carry lookahead or forwarding. The solution used here is a simple idea, group bypass, which is old enough that Babbage used a mechanical form of it in his Difference Engine 150 years ago. It has the benefit of not adding much extra logic (which is good for our goal of minimum energy) while giving close to the best result. The graphic shows a 16-bit add with groups of 4 - for 32-bit add we have 4 more copies of the logic outlined in green. The carry delay goes from 32 full-adder-carries to:
4 full-adder carries, the initial low-order group at the right
6 of the green logic, where a forwarded carry must cascade through 2 NOR2 cells
4 half-adder carries in the final high order group at the left
The NOR2 cascade and the half-adder carries are a fraction of the delay of a full-adder carry so this is probably 3x to 4x reduction in carry delay.
The logic cells flow left to right, like the slices, opposite to the high-level sketch above.

The logic in the green outline resolves to a set of library cells (with a few optimizations by rotation, reflection, and merger). Each slice gets a half-adder and a x3 buffer to drive its e- or a- output including one rotation wire. The NAND4, two NOR2s, and an inverter are found at the right, and will be in the median between the groups of 4.
A tidy fit
These will fit neatly into the areas at the end of the e- and a-pipes.

Here is that again in video showing how the lookahead and buffering fit into the floor-plan left for them:
Wrapping up
That is the end of the physical layout detail on the SHA-256 Digest. We have enough information to proceed with energy and size calculations, and I do not want to burden you with detail that adds nothing new to learning about logic construction. I appreciate your focus and interest so far!
For anyone who wants to discuss the details further, or to talk about the Scheduler logic and layout, message me with the new Substack messaging system.
Or, add comments so everyone can join in! If SubStack blocks you from commenting on a specific post, look for the “Table of contents for Pipe posts” where I welcome comments on any of the Pipe posts - just mention which one it applies to.
Next Week
We will do the numbers. How can size and energy be estimated from the design in its current state? What about speed?
Then we will look at some ways it could be optimized further.
Next week will be the end of the series on the SHA-256 logic. I am working on some new topics in the very small for future series! There will be a pause of one week and then those will begin. I will eventually return to silicon with a topic of memory, but first we will look at some other technologies.