
Exp8 is nearly ideal
Multiply is no longer the largest part of FMA

The previous post was enthusiastic about using log addition for multiplication in a MatMul with FP8 equivalent range and precision. I realize I may have forgotten to explain how much of a change this makes.
I had for some time been planning to do a few posts designing an optimal FP8 multiplier. It was a thing of beauty, carefully designed to minimize transitions and optimize energy per multiply. Well, now I need not bother. The Log approach beats it easily, while also handling multiple formats (E4.3, E5.2, FP6 and FP4) with ease. The fused multiply-add is now dominated by the add (or properly, accumulate) part which uses easily more energy than the Exp8 multiply so there seems no point to further polishing the multiply.
How the FMA is used
The key insight is that the accumulation cannot easily be made smaller. The FMA is operating like a zipper joining two vectors (a row and a column) to accumulate a single sum. In AI the row/column is often thousands of elements long. Finite matmul units are generally smaller, like 32x32 (row x column length) in a GPU up to 256 x 256 in a TPU, but those units run in concatenated patches which result in those same overall thousands-of-elements sums.

A MatMul (matrix multiply) unit is a grid of fused-multiply-add (FMA) units which run in parallel, with each row-column pair of input vectors being processed at one cell of the grid. A 32 x 32 MatMul can run the inner products of every combination of 32 rows and 32 columns, for an arbitrary length of row against an equal height of column.
All the cells run in parallel. The function found in each cell is to take a the next value from the row, multiply it by the next value in the column, then add that product to an accumulator. There may be thousands of value pairs from the row x column and the accumulator should have enough precision to accommodate the range in possible products without losing detail. For example, there may be one pair of (30 x 30) and a thousand pairs of (1 x 1). Even though we eventually may round the sum to FP16 with 8 bits of precision, if we use an 8 or 9 bit accumulator all the 1 products will be rounded down to zero relative to the 900 product, losing more than half the perfect result. In practice these rounding errors, and the variation in results due to order of calculation, cause problems for training and inference.
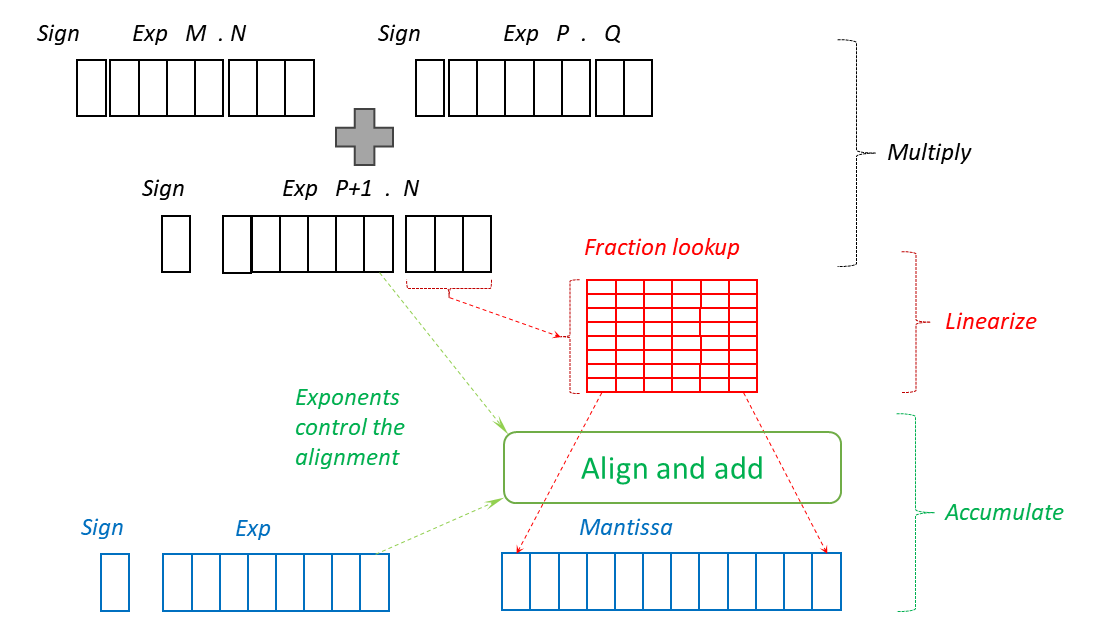
The Exp8 format covers roughly the same dynamic range as FP8. With the E5M2 formats there are about 34 doublings from the smallest to the largest number. After multiply the product range is about 68 bits. Furthermore, if we are to sum the products from vectors of at least 1,000 in length, the final accumulation in theory can be 2^78 larger than the smallest element product.
In practice the accumulator is likely to be somewhere between 8 (BF16 mantissa) to 24 (FP32 mantissa) bits in size, where 8 bit exponent and 12 bits might be a sweet spot that can eventually be rounded into BF16 format.
Multiply is a solved problem
Well, it is at the 8 bit operand size, for Exp8. Aligning and adding the operands uses a minor fraction of size and energy of the FMA. Even with a minimal 12-bit mantissa the alignment and summation needed in the accumulator is much larger, and consumes much more energy, than the multiplication does. The multiplier can accept mixed precisions of Exp8, Exp6, Exp4 or even shorter. The energy per operation will remain near optimal since the accumulator, not the multiplier, dominates the cell.
We may note that the smaller precisions tend to be used with larger arrays so the accumulator will not easily be reduced further. So, this solution seems likely to be sticky for small, scaled formats. Small integer formats will be better optimized with a separate design of MatMul and FMA.
If I do further work on reducing energy in FMA I will look at how to optimize the accumulator. It is especially interesting to look at integer accumulators with E4M3 and equivalent Exp8 operands. In the MX formats with scaling for every 16 or 32 operands, these can be grouped so the integer sum (with no rounding loss) cascades into an FP32 sum at the end of each MX group with good accuracy and low energy per FMA.
Why Do We Have FP8?
FP8 only encodes a few integers directly. It has irregular proportions, and it is not optimal for either multiply or add. We appear to have it because we started with FP32, which directly encodes a very useful range of integers. FP16 encodes everyday integers. BF16 started to go off the rails a bit, becoming suspiciously like Exponential but holding to past traditions. FP8/6/4 just seem to be “why bother”?
Exp formats are very cheap and accurate to multiply, and they are spaced at even proportions, something which has centuries of proven use in engineering. It may be late to the party, but it is not unprecedented.
Are Larger Exp Formats Possible?
For example, what about a “brain exponent”, BE16, with sign, and 8.7 bits of exponent? This might be of use more for activations than for model weights. It is closer to the form of human senses like sight and sound.
In principle the same functional blocks can be used. The main innovation will be in the lookup table. A 7-bit lookup will be around 20 times larger than the 3 bit, which would be around 20 sq microns to deliver an 8- to 10-bit linearized output. This is not an impossible size - it is probably still smaller than the size of the accumulator that would match it - and the energy use would be reasonable, but clearly the chip could not have as many FMAs for these as for FP8.
BE16 would still have the benefit that the multiply is much cheaper than the accumulate (and the accumulate would be the same as BF16 needs). It would also easily mix for Exp formats of all lower bit counts.
Since a lot of training uses BF16, BE16 might be a compatible, efficient alternative.
BE16 would be getting pretty close to slide rule precision, a technology which built the atomic age.
Next Week
OK, either you like exponential format or you don’t - I think it has serious potential for near optimal efficiency in silicon. If you find it interesting and do experiment with it please let me know what you learn. l will likely return to use it in a future project, but it gets a rest for now.
The GNSS work is coming along nicely. I should finish the first passes on comparing predicted to actual orbits this weekend. That is the basis of the “telescope” since tweaking the positions and parameters of celestial influences will show up in the differences and be especially interesting to calculate the effectiv
e direction of the Sun. It will still require the code to switch to quad-precision calculations and run iterative searches for best matches, as well as running some deliberate perturbations to check that the calculations are well behaved, so the results remain several weeks away, as it is a weekend project.
As always, feel free to add comments or to message me directly!